ML is a subset of the huge field of Artificial Intelligence (AI) recently
proving very effective especially at relatively simple, but time consuming tasks. The relevant subsets of AI are collected in Figure 2.1. Examples and effective applications are truly wide-spread, ranging from faster matrix multiplications [35], to tracking the movements of mobile phone users using facial recognition [85].
In essence, ML aims to bridge the gap between the binary world of computers and the complex processing capabilities of the human brain. With constant advancements in computational power [45], computers are now capable of solving complex tasks where traditional analytical methods fail [26, 127]. ML employs learning-based approaches, where the goal is to use a collected dataset to identify patterns and relationships between two sets of data, defined as inputs and outputs (e.g. images and their respective segmentations for segmentation tasks). This allows computers to recognize abstract features in the data, providing a more meaningful representation of the information for specific tasks, see Figure 2. The end result is a mathematical model that can make accurate predictions based on the input data.
The ML model learns patterns and adjusts its parameters to improve its own performance through an optimization process that follows a set of user-defined rules by going through the available dataset. This is performed with the expectation that the learnt knowledge transfers well to previously unseen data from real world scenarios.
It is easy to see the uselessness of a method that only works on the examples that it was learning from, but a more subtle version of this scenario is a common issue known as overfitting, where a ML approach performs significantly better on encountered data during training, than previously unseen data. As such, addressing and understanding generalization concerns is a crucial part of all ML solutions [130].

Components
The idea of ML is to allow the computer to solve a given task by learning from experience. It learns the relationship between input and output data pairs. After the learning stage, the model can predict output data from new inputs, that it hasn’t seen during training. In practice, the learning process involves minimizing a loss function over a hypothesis space using the available training data. This means that implementing ML requires three components:
- Data: Acquired from a distribution unknown to us.
- Hypothesis space: Which define all the possible mathematical relationships between any given input and output. The trained model will take one of the many forms defined by the hypothesis space.
- Loss function: It serves as a measure of how well a model is able to map the inputs to the expected outputs.
The parameters of the model are adjusted using all their possible variations according to the hypothesis space, so that the output predictions minimize the selected loss for the available data. To make training realizable in practice, compromises are often made for the hypothesis space, selected loss, and data.
Data
In ML, data is a highly abstract concept, and can have widely different forms depending on our task. The model can take a sequence of inputs, such as in Natural Language Processing or time-series analysis, and give continuous predictions. Alternatively, it can take all the available data at once, and provide a single prediction. With ML applications in virtually all fields of academia and industry, the concept of data is extremely general, and the data points can represent a myriad of things, like audio [28], physical movement [77], or human emotions [175].
In the context of ML, a data point or data sample represents the smallest unit of data used for learning, also known as an observation or an example. Meanwhile, a dataset is a collection of data points, forming the basis for ML model training and evaluation.
Each data point can be split into two parts: features, that would serve as inputs which can be measured or computed easily, and labels that serve as the desired outputs which we wish to be predicted by the model instead of manually acquired, perhaps because they are more difficult to measure. Using these concepts, the model is tasked to learn to reconstruct the underlying labels from the features.
Many applications of ML use image data for both input and output, as they are highly effective in recognizing and determining higher-level features. The data units of an image, i.e. the image pixels are most commonly organized in a 3D array, corresponding to width, height and channel. The channel is the number of data points in each pixel. For the case of natural images in color, there are most commonly three channels: red, green and blue. For a grayscale image, the number of channels is consequently, one.
A dataset is collected for the model to directly learn from, often called the training dataset. It is usually assumed that all new data points come from the same distribution as the distribution of this dataset, as the model cannot be expected to perform well on data from another distribution. Therefore, increasing the variety of the training dataset will consequently make the model perform well on a wider variety of data. This means improving the generalization of the model towards previously unseen data, making it more useful for real world applications. This variation is often limited in practice by the small amount of available data.
Monitoring the loss on the training dataset might be informative to reassure that the optimization process works as intended, however, it is not necessarily a good indicator of the model performance on data not included in the training, i.e. its generalization. Instead, a separate dataset is used during training to continuously validate the model, and the performance on this dataset is used as an indicator of the generalization error. As an example, an indication that the model has been trained for too long is that it performs significantly better on the training data than on this validation dataset. Although it doesn’t affect the parameters of the model, if the training is stopped when it reaches the best performance on the validation dataset, it indirectly affects the training.
A common solution for this is to further retain another portion of the available data to evaluate on after all model parameters have been determined. This dataset is called the testing set. It is important to stress, that the testing dataset is only used after all models have been trained, to avoid indirectly affecting the optimization process. This data split is illustrated in Figure 3., and it is a common choice when there is a large amount of data available.

The names of the validation and testing datasets are often interchanged in literature [138]. However, the above definitions have recently become more standard, and this thesis and the projects follow the authoritative work of Ripley [165].
A common alternative data splitting approach is to use k-fold cross-validation, where multiple models are trained on different portions of the available data, which is often preferred when the amount of data is limited [134].
Data samples
Whatever the data samples might be, the overall task of ML is to predict labels from the features. As the model learns from the training data, the distribution from where this dataset was drawn will be the distribution that the model will work on best. Therefore, it is essential to understand the training dataset when using the model in the real world and to acknowledge when the real world data is significantly different from the training data.
Although these aspirations are usually not included in the ML models by design, deep network architectures show surprisingly good generalization properties [112].
Augmentation
The performance of a model depends on the number of available data samples. This can be artificially increased by using the same data points multiple times, by introducing some form of disturbance which is valid for the scenario. Such approaches are called data augmentation.
The forms of augmentation depend on the data. For images the most common ones are translations, rotations, flips, adding extra noise, multiplications by a constant value and so on [144]. Augmentations need to be adjusted to the task at hand to keep them realistic. For example, for the analysis of natural images, left-right flips are often used, while up-down flips can create unreasonable images in some applications. For medical images however, left-right flips can also create irrational anatomies.
Hypothesis space
With the goal of finding the true underlying relationship 
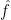
To get an idea about the hypothesis space, let’s assume that our model definition contains a single function, a polynomial of degree 4 that connects the input 


Our hypothesis space in this case contains the function 




In real life scenarios, the parameter values are not necessarily discrete, therefore the possible number of hypotheses are not countable, however the number of model parameters are often in the range of millions, or even billions [14].
The size of the hypothesis space is closely connected to the complexity of the model, which is crucial for understanding its generalization ability [59].
Explainability
The complexity of a model is connected to its number of parameters that can be adjusted during training, however the sets of functions in the model definition that remain unchanged during training also affect the model complexity.
There is an increasing concern around the explainability of ML models, especially in high-stakes applications such as finance and healthcare. Several types of machine learning models implement simpler rules for predictions (e.g. decision tree models) that are easier to interpret, however as the complexity of the models increase (especially towards more complex deep learning models) concerns around explainability become more pronounced and challenging to address. During the development of ML architectures and model components, their explainability is essential to consider for their long term use and value [110].
Losses and metrics
As the model is trained, its parameters are adjusted to minimize the value of the loss function, leading to improved predictions. In essence, the loss function serves as a guide for learning, helping the model to improve and make better and better predictions. Hence, the loss function is aimed to meaningfully determine which set of parameters is better in describing the relationship between the inputs and outputs.
Our task is to select a loss that best assesses the performance of the model, comparing the output predictions of the model to the available ground truth labels. Choosing the right loss function is crucial to ensure that the model can accurately capture the relationships between the input data and desired output. There are both practical and conceptual concerns around selecting the ideal loss function.
Practical issues
Due to the nature of the most commonly used optimization process to train ML solutions, the selected loss function needs to be differentiable with regards to the model parameters, which is not true for a wide range of commonly used evaluation metrics.
As an example, we consider the case of a binary classification problem, where the label 

![\mathcal{L}_{class}(y, \hat{y}) = \frac{1}{n} \sum_i [ y_i = \hat{y}_i ],](https://s0.wp.com/latex.php?latex=%5Cmathcal%7BL%7D_%7Bclass%7D%28y%2C+%5Chat%7By%7D%29+%3D+%5Cfrac%7B1%7D%7Bn%7D+%5Csum_i+%5B+y_i+%3D+%5Chat%7By%7D_i+%5D%2C&bg=ffffff&fg=000&s=0&c=20201002)

![[\cdot]](https://s0.wp.com/latex.php?latex=%5B%5Ccdot%5D&bg=ffffff&fg=000&s=0&c=20201002)
The first (smaller) concern we encounter is that the loss function, by design, is minimized during training, whereas the accuracy should be maximized for the performance to improve. This is easily solved by inverting the loss, into the zero-one loss, as

This loss is not differentiable with respect to the model parameters ![\hat{y} \in [0, 1]](https://s0.wp.com/latex.php?latex=%5Chat%7By%7D+%5Cin+%5B0%2C+1%5D&bg=ffffff&fg=000&s=0&c=20201002)
Conceptual issues
Just as the binary cross-entropy is a surrogate for the accuracy, the accuracy might only be a surrogate of what is actually a meaningful metric. The accuracy (and also other metrics that include reducing the mean of multiple values) may mask important effects, such as quality improving in one area but degrading in another.
Let’s take the accuracy as an example again. It is a metric that can be extracted from the confusion matrix, which is a table that shows the performance of a classification model comparing the individual actual and predicted classifications. The accuracy, however, masks the difference between false positives and false negatives in the prediction performance. However, for the common case of imbalanced data, where samples from one class is more common than in another, the distribution of these misclassification error types could be informative and useful when defining what to optimize in more detail.
For the case of images, the MSE, or other pixel-based quality metrics (MAE, SSIM) have been often used as a surrogate for perceptual quality. If we would like two images to be as similar as possible, the MSE is a straightforward candidate. However as the technology advances and as we get better quality results, we can show, that these metrics are, in fact, poor candidates for perceptual quality [103]. More complex metrics, like the VIF convey much closer resemblance to what humans actually see as similar. Recently, alternative loss functions have been proposed for image reconstruction (especially in deep learning) that instead of pixel-based losses, look at more abstract, higher-level differences between prediction and ground truth images [74].
The Datasaurus Dozen project draws attention to how metrics can be misleading, through an amusing collection of points. One might think that if two sets of points have the same mean, variance and correlation, then they follow the same underlying distribution, however visual inspection clearly shows otherwise.
Additionally there are popular misconceptions around the use of general statistics, such as the reporting of “significant” gains in performance of DL models, without the use of actual tests for significance [4, 169].
Learning approach
ML methods can be categorized based on the general approach they take to learn from the training data and how they define their loss function. In the context of image-to-image models, there are two common approaches.
Supervised Learning
Supervised learning is a type of ML where the model is trained using the labels of the available data. The model is given input-output pairs and it learns to map the inputs to the output labels explicitly. The model is trained by computing the loss between its predictions and the ground truth labels, and updating the parameters to reduce the loss to improve the performance. This approach is widely used in a variety of applications, ranging from computer vision [168] to climate modeling [2].
Unsupervised Learning
Unsupervised learning, on the other hand, is where the model is trained without explicit labels. Instead of relying on the labels, the model learns from the structure and patterns present in the input data. During this learning approach there are no direct output labels for the training data samples. The goal of unsupervised learning is to learn meaningful representations of the data that can be used for a wide range of downstream tasks, such as natural language processing or image style transfer [73], or applications where the available data is limited [86].
In summary, supervised and unsupervised learning—and other popular learning methods such as semi-supervised and reinforcement learning—have their own strengths and limitations and the choice of which to use will depend on the available dataset and the specific task at hand.
Bias-variance trade-off
The set of possible model candidates, or the hypothesis space, must be carefully selected to match the complexity of the task at hand. The complexity of the model is a crucial factor that affects its ability to learn from the data. If the model is too simple, it will not be able to capture the underlying distribution of the data, leading to a large bias, also known as underfitting. On the other hand, if the model is too complex, it may learn about the individual data samples instead of the overall data distribution, resulting in a high variance, also known as overfitting.
The optimal complexity of a model depends on the complexity of the problem and the amount of available data, and the selected complexity of the model needs to find the balance between underfitting and overfitting. The behaviour of the model largely changes according to its complexity, as shown in Figure 5.
Polynomial degree:
ComplexityThe impact of the complexity parameter on a ML model is demonstrated by the performance of the loss function on the validation dataset. The true relationship between the input
where 




The bias term represents the error introduced by approximating the problem with a simplified model. A high bias means that the defined hypothesis
Polynomial degree:
ComplexityThe bias-variance trade-off is essential to address when considering the complexity and generalizability of a ML model.
Deep learning
Currently, DL is arguably the most popular field of ML, with a wide variety of applications, from commonly used speech recognition features in smartphones [28] to active research in restoring incomplete historical texts from images [8]. DL is a subfield of ML that make heavy use of neural networks, which are a cascade of hidden layers of nonlinear processing units inside the model. Layers that operate on the outputs of previous layers and pass their outputs to successive layers are called hidden layers, as they don’t explicitly operate on the provided data, and don’t provide an explicit model output. These hidden layers are very effective at extracting abstract features from the input data. This level of complexity made DL methods extremely effective within the field of ML.
When a model has at least one hidden layer between the inputs and outputs, the model becomes “deep”, hence the term DL. The advantage of DL is that the models prioritize a large number of hidden layers over using large layers that have large memory requirements. The hidden layers are able to learn more complex features, which has made DL increasingly popular in recent years. This is further supported by technological advancements such as the increasing VRAM of GPUs, that allow for large model architectures.
Artificial Neural Networks
The interconnected processing nodes or neurons of DL models are often called Artificial Neural Networks (ANNs). The “neural” terminology takes inspiration from how the brain works, with neurons passing information forward. The simile is faulty, and any drawn parallels extremely oversimplify the way human brains work [119], however, the effectiveness of ANNs is undeniable [102]. ANNs are efficient at learning and extracting complex features from data, and surprisingly they appear to favor simple solutions learned from large amounts of data, inherently having the ability to avoid overfitting [124].
Numerical optimization
So far we have discussed the training of a ML model simply as minimizing the loss function over a hypotheses space using our data. The optimization problem can be written as

where 


The non-smooth, highly non-linear and non-convex nature of deep networks makes optimization a challenging task as they contain many local minima, and it limits the range of optimization methods that can be used, but still offer many options. Hence, it is possible that the optimization process never reaches a global optimum, and it only finds a sub-optimal local minimum. The training of a DL model is often stopped when a sufficiently low loss is achieved, but it is not minimized in a global sense.
Given the complexity of DL models, there is no one-size-fits-all approach to minimize their loss. The selection of an optimization algorithm depends on the model’s specific characteristics and the computational resources available. It is important to experiment with different optimization algorithms and hyper-parameter values to identify the best model for a given task.
One of the most popular families of optimization algorithms for deep learning is based on SGD [133]. This family of methods is based on using first-order information with regards to the model parameters

The gradient vector shows the direction of the steepest increase of
Backpropagation
All necessary computations made by a DL model can be stored in a computation graph which also provides a way to visualize how the model processes data and how it learns and updates its parameters. In a computation graph each node represents a specific operation, such as addition or matrix multiplication, that transforms the inputs in a particular way. The edges between nodes represent the flow of data through the graph, with the output of one node becoming the input to the next. The first two nodes operate on the inputs directly, as:
and
introducing two model parameters: 
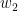


introducing a third model parameter: 


The DAG structure of the computation graph means that it is unidirectional and there are no cycles in the graph, therefore the model’s output depends only on its inputs and not on any internal state of the model. This generally holds for DL models with the notable exception of recurrent neural networks [106]. Computing the predicted output of the model using the input data and the current model weights is known as a forward pass or forward propagation through the computation graph. Figure 8. shows how example data can flow through the described graph from the above example equation. The DAG structure also makes it possible to compute the gradients of the loss function with respect to the model’s parameters using the backpropagation algorithm [133], which exploits the chain rule of calculus to efficiently propagate error gradients—the difference between the predictions and the ground truth output—through the graph.
x1= x2=
w1= w2= w3=
Pause / Restart
depends on the two inputs  and
and  and also the three model parameters (, and ). Changing any of these terms will affect the predictions.
and also the three model parameters (, and ). Changing any of these terms will affect the predictions.The chain rule enables the computation of the derivatives of a node with respect to any earlier node in the computation graph. By breaking down the computation into smaller parts, we can efficiently compute the gradients of the loss function with respect to the model’s parameters. For the graph in Figure 8., we can use an MSE loss function 


and



x1= x2=
Y=
Pause / Restart
 ,
,  and
and  ) are calculated using the partial derivatives of the loss .
) are calculated using the partial derivatives of the loss .The computation of these derivatives require 


The use of backpropagation in a deep learning model imposes a requirement that each layer must be able to compute its output and derivatives with respect to its inputs. Therefore, layers in DL models that cannot meet this requirement are most commonly replaced by proxies similar to replacing loss functions, as described in the Section “Losses and metrics”.
SGD
Using the backpropagation algorithm, the gradient vector calculated at any given point of the loss surface gives the direction of steepest ascent. The fundamental idea of the gradient descent algorithm is to start at a random point on the loss surface and to move iteratively in the direction of the negative gradient. The loss surface of a function with a single parameter
Position
Gradient:
Position:
 with a single parameter: . The arrows show the direction of the derivative of —which is the direction of steepest ascent—at point , so to minimize the function, the value of should be moved in the opposite direction. The value can be changed using the slider.
with a single parameter: . The arrows show the direction of the derivative of —which is the direction of steepest ascent—at point , so to minimize the function, the value of should be moved in the opposite direction. The value can be changed using the slider.Optimization methods based on first-order derivative information of a function, are collectively called first-order optimization algorithms. In smaller scale optimization problems, the second derivatives can also be utilized, hence called second-order algorithms [7]. However, in deep learning, the second derivatives are often too expensive to compute, and the first-order methods are a more feasible option.
Training a model using the gradient descent method is performed by updating each model parameter as:
where the step size to take in the direction of the descent direction is determined by the learning rate 


Number of Steps
Learning Rate
New loss:
.It is important to stress, that the presented figures of 1D loss functions conceal the complexity of the optimization problem in DL, where the number of parameters in
To compute the descent direction over all available data, the gradients for all data points must be computed and averaged, which can be computationally expensive and time consuming. Instead, SGD offers an efficient alternative by computing the gradient with respect to a single data point and update the model parameters. This process is repeated for each data point in the dataset, and a full pass over the dataset is called an epoch. This allows training on extremely large datasets by storing only the gradient with respect to a single data point at a time. However, the optimization process in SGD is noisy, which can lead to the model taking sub-optimal steps multiple times before reaching an optimal solution.
A way to improve upon the default SGD is by introducing a mini-batch of data points, which is a subset of the available data. If the size of the mini-batch is one, the method is identical to the default SGD, and if it is the size of the entire dataset, it becomes the memory-exhaustive gradient descent method. Ideally, the size of the mini-batch is increased as much as to still fit into memory. The mini-batch SGD method is widely used in DL.
Improving SGD
Although SGD is a simple and efficient optimization method, it is relatively slow, and some proposed features can achieve practical benefits.
To accelerate the optimization process, a momentum component can be added to the gradients [156], which accumulates an exponentially weighted moving average of the passed gradients from previous training iterations. This component can be viewed as an analogy to the concept of momentum in classical mechanics—where moving objects continue moving in the same direction with the same speed unless acted upon by an external force, in our analogy, the gradient. During gradient descent optimization, the momentum component maintains the direction of the previous gradients and by that is able to better avoid getting stuck in local minima. By incorporating momentum, we can improve the convergence rate and stability of the optimization process. The effect of the momentum component is presented in Figure 12.
Number of Steps
Learning Rate
Momentum
New loss:
Figures 11, and 12 show a scenario where
Common model components
With the breakneck speed of advancement in DL, trends shift quickly, and it is difficult to keep up with the most advanced methods. Below we go through some of the most relevant components that have been used throughout the presented projects.
Convolutional layer
The convolutional layer is one of the most widely used layers in deep learning, and is based on the mathematical operation of convolutions. ANNs with convolutional layers are popularly called convolutional neural networks (CNN)s. Convolutional layers are highly effective at feature extraction, making them a key component of models designed to solve image-based tasks, such as object recognition or image classification.
Kernel size
The convolutional layer is one of the most widely used layers in deep learning, and is based on the mathematical operation of convolutions. The most commonly used form of convolution in DL is the 2D discrete convolution. Due to its similarities to linear spatial filtering—which is the actual operation performed by the layer—both are commonly referred to as convolutions in the context of DL. If we have two bi-variate functions of integer variables, denoted by 

where the limits of the summation extend over all possible values of 

An ANN with convolutional layers is popularly called a Convolutional Neural Network (CNN). Convolutional layers are highly effective at feature extraction, making them a key component of models designed to solve image-based tasks, such as object recognition or image classification.
In a convolutional layer, multiple filters are applied to an input image to perform convolutions, with each filter learning its own set of parameters denoted by the filter mask 
Kernel size
Depth
Receptive field size:
A fundamental concept that underpins the effectiveness of convolutional layers in deep learning is the notion of a receptive field. The receptive field of a convolutional layer refers to the area of its inputs that influence a certain output activation. The receptive field of the first convolutional layer is determined by the size of the kernel used in that layer. However, the receptive field is also influenced by the previous layers, hence the receptive field of a given layer can grow rapidly as we move deeper into the network. The increasing receptive field of the layers means that they can capture features from larger areas in the input.
To illustrate this concept, Figure 14. shows the receptive field of multiple convolutional layers, to help visualize how the receptive field expands as information is processed through deeper layers of the network.
Padding
In the context of CNN, image padding refers to the process of adding extra rows and columns of pixels around the edge of an image before applying a convolutional layer. As seen in Figure 13., the output is smaller than the input, because there was no padding used. In the simplest scenario of constant padding, the values outside of the image are assumed to be a constant value (most often zero), and when convolutions are performed around the edges of the image, these values are taken into account. Padding allows us to adjust the behavior around the edges, for a few examples see Figure 15. The type of padding used can have a significant impact on the output of the convolution, particularly in deep networks with many layers.

Activation functions
These are element-wise functions applied to the output of a layer. They introduce non-linearity into the output of the individual layers, allowing the network to model complex relationships between inputs and outputs.
One of the most common activation functions in deep learning is the rectified linear unit (ReLU) function [18], which returns the input if it is positive and return zero otherwise. ReLU has been shown to be computationally efficient and effective in preventing the vanishing gradient problem [56], where the computed gradients become too small to make a significant change to the model, halting learning. The effectiveness of ReLU makes it a popular choice in many neural network architectures.
Sigmoid functions that bound all input values to a specific range are also widely used in DL. The logistic sigmoid function given by 
has an output range between 0 and 1 which is often interpreted as an estimate of the probability that a value belongs to a particular class.
The softmax function, defined for each output neuron as
is often used as an activation function for classification tasks. The softmax function maps the output of a neuron to a probability distribution over multiple classes. This allows the neural network to make predictions about the most likely class for a given input.

Dense
In dense layers, also known as fully connected layers, each output neuron is a weighted sum of the input neurons plus a bias term. Therefore, in dense layers, in contrast to the convolutional layer, each neuron is connected to every neuron in the previous layer. Dense layers are commonly used in deep neural networks for tasks such as image classification, natural language processing, and regression. With a large number of input or output neurons, dense layers can be computationally expensive.
Batch Normalization
Batch normalization was introduced to speed up the training time of DL methods [22]. Batch normalization has several benefits, including improved training speed and stability, increased regularization, and the ability to use higher learning rates, which can lead to better performance. It works by normalizing the activations of each layer in the network using the mean and variance of the current mini-batch during training. This means that the activations are shifted and scaled so that they have zero mean and unit variance, which is supposed to help prevent the “internal covariate shift” problem that can occur during training, where the distribution of the activations in each layer changes over time. This explanation has later been questioned [137, 154], and there is still no proper justification of why batch normalization works so well.
Dropout
Dropout is a regularization technique used to prevent overfitting by randomly deactivating—or dropping out—some activations during training [55]. Dropout layers randomly set a fraction of the activations to 0 at each update during training time, which forces to evenly distribute the contribution of the layers in the network, which reduces the likelihood of overfitting. Generally, during inference or prediction time, all neurons are active to make predictions.
Recently dropout has been found useful not only during training, but testing too. By sampling multiple predictions from the same input, each with different dropped-out units, we can compute the variance of the predictions and use it as an estimate of the model’s uncertainty. This approach can be particularly useful in tasks such as image segmentation or anomaly detection, where the model is required to make predictions with high confidence. This uncertainty estimate is called Monte Carlo Dropout [40].
Common model architectures
A large number of DL architectures have been proposed so far, many showing significant potential in medical imaging applications. Several popular architectures (e.g. self-attention models, diffusion models) are excluded from this list, only due to the fact that they were not explored in the presented projects. The following are the architectures used in the presented work, along with a brief description of each.
U-Net
U-Net is a very popular convolutional neural network architecture developed for image segmentation tasks [148]. It consists of a contracting path between layers to capture context and a symmetric expanding path to enable precise localization of objects in the image. The contracting path consists of a series of convolutional and downsampling layers to progressively reduce the spatial resolution of the input image, while increasing the number of filters in each convolutional layer. The expanding path uses transposed convolutional layers (or other upsampling operations) to increase the spatial size of the feature maps, followed by skip-connections to the corresponding feature maps from the contracting path, to enable precise localization. The final layer commonly uses a convolution with a kernel size of 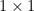
SRResNet
The SRResNet is a deep learning architecture proposed for single-image super-resolution [88]. It contains multiple residual blocks, which means the model does not aim to reconstruct the output image, but the difference between the input and output images, their residual. These blocks allow for efficient gradient flow and enable the network to learn deeper features. In addition to residual blocks, SRResNet also uses skip-connections, which help preserve spatial information and prevent the vanishing gradients problem that can occur in very deep networks. The skip-connections also allow the network to learn features at multiple scales. Another important aspect of SRResNet is its use of a perceptual loss function, which measures the similarity of the generated image to a high-resolution reference image using a pre-trained image classification network. This loss function helps improve the perceptual quality of the reconstructed image, and has been shown to produce better results than traditional pixel-wise loss functions like mean squared error.
General Adversarial Network (GAN)
A GAN is a type of neural network architecture, and also a custom optimization approach, used in unsupervised learning for generating synthetic data [92]. They have been used in a variety of applications, such as image augmentation [37], video synthesis [166] and style transfer [172]. GANs consist of two main components: a generator network and a discriminator network. The generator network learns to generate realistic-looking data, while the discriminator network learns to distinguish between the generated and the real data. During training, the generator and discriminator networks play a two-player min-max game, where the generator tries to generate realistic-looking data to fool the discriminator, while the discriminator tries to correctly identify the synthetic data. As training progresses, the generator becomes increasingly better at generating realistic-looking data, while the discriminator becomes increasingly better at distinguishing between the synthetic and real data. The ultimate goal is to train the generator to generate synthetic data that is indistinguishable from the real data.
Common programming frameworks
The field of deep learning has evolved greatly during my studies (2018-2024). The current state of programming in deep learning is dominated by Python, with the two leading frameworks being PyTorch [118] and TensorFlow [1] with the Keras API [47].
One of the challenges faced by the deep learning community is the compatibility of models between different frameworks. The Open Neural Network Exchange (ONNX) is an open standard that provides a common intermediate representation for neural network models, allowing for easy conversion between frameworks and a wide usability. This is important for ensuring compatibility and ease of use across different tools and platforms.
TensorFlow and PyTorch also have their own built-in saving procedures, allowing developers to store and retrieve their trained models. Tensorflow recommends using the SavedModel format that includes the trained model weights, the computation graph and any additional metadata required to run the model. Additionally models can be exported in a Frozen Graph format (.pb) that contains a serialized version of the graph with the trained weights. PyTorch recommends saving the models in a TorchScript format that saves the entire model as a standalone executable program, however another common format is to only save the model parameters without the model architecture (.pth). These formats allow developers to return to their models at a later time and make further adjustments, including changes to the model’s weights. In both frameworks, checkpoints are available that allow the user to easily revert to an earlier state of the model training process.
When it comes to deploying trained models, standalone exports are less common, as they are less useful for development. However, they are highly beneficial for reproducibility, as they do not rely on the presence of the original deep learning framework or its specific version. To deploy models for later use, TensorFlow provides Frozen Graphs (.pb) and both frameworks support the ONNX format.
In conclusion, the deep learning landscape is rapidly evolving, and Python, TensorFlow, and PyTorch are currently the most popular tools in this field. Developers have access to a variety of formats for storing and deploying their models, including built-in saving procedures and standalone exports. Despite the abundance of options, it is important to choose the right tools, being aware of concerns of reproducibility, and to keep up-to-date with the latest developments in the field.